"Am I overfitting ?"

Machine learning and Data Science | Open Source contributor | Python Developer
What is Overfitting?
Overfitting occurs when your machine learning model sees the training dataset so many times that it memorizes the patterns in it instead of generalizing well for new datasets. Overfitting can be identified when you see high accuracy scores on the training dataset but low accuracy scores on the test or new dataset.
Let's take an example

Let's suppose there are two players "Player1" and "Player2" in the game of CS-G0. The game has several different maps, one of them is the iconic Dust2 map which most of the players play. Now "Player1" only plays the Dust2 map, and doesn't know any other map in the game. He has mastered the map so well that it's nearly impossible to defeat him on that map. At the same time "Player2" plays all the maps and knows every map in the game, but is average on all the maps.
Talking in technical terms "Player1" has overfitted the game in the map of Dust2. While "Player2" has generalized well on all the maps of the game and is a reliable player for competitive matches which have random maps.
Similarly, when a machine learning model learns the pattern in training data so well that the patterns don't work on the new data, the model fails to predict the accurate value.
Let's take a look at what overfitting looks like!
The picture below shows predictions from three different models machine-learning models on the same training dataset. The first model is the regression model, the second one is a polynomial model and the third is a complex higher-degree polynomial model.
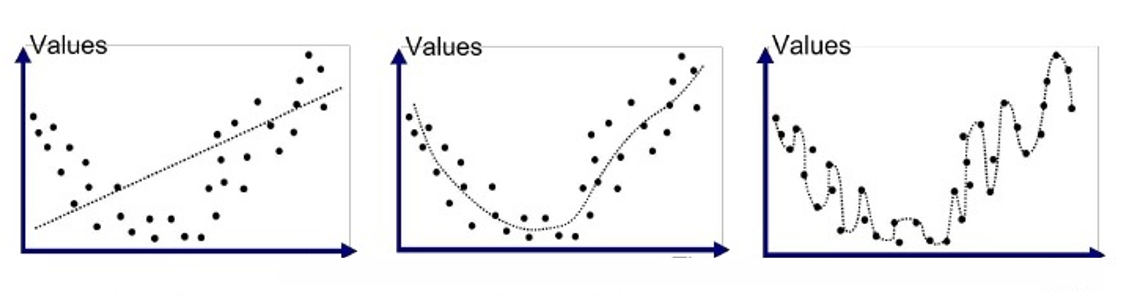
Evaluating the three models:
Loss is a measurement of how good your model is in predicting the expected outcome. The distance between the actual value and the predicted value in the above graph will directly affect your loss.
Model 1: The prediction line of the model passes through the centre trying to cover all the points. Due to this, it has a heavy loss and cannot predict almost all the values accurately.
Model 2: The prediction line passes through most of the points and has a very low loss at each instance.
Model 3: The prediction line passes through all the points and has a loss of almost zero. Model 3 seems to cover all the points in the training dataset with accurate values.
Till now Model 3 seems to be the best choice for our task as the model has learned all the values correctly with no loss and high accuracy. Now let's add some test datasets or new datasets in the model, to check its performance on the new Datasets.

The red dots in the above picture are plots of new values added to the dataset on the prediction plot of Model 2 and Model 3.
Looking at the above plot the loss scenario looks different this time. The last three test data plots in Model 3 have a very high loss, the prediction line is far above the actual plot of the dataset. Model 3 has adapted the training data so well that it is unable to perform well on new datasets and therefore, ends up having high loss values. While Model 2 is still performing the same as it was performing earlier. It still has a low loss value and predicts most of the instances accurately.
How to tackle overfitting
Now we have a good idea of what overfitting looks like. Let's see some ways to identify and tackle the problem of overfitting.
Train with more data
Cross-validation
Feature selection
Regularization
Data Augmentation
Early stopping
Train with more data
Adding data which is clean and has important features is required for getting an accurate prediction. The new dataset in addition to your old dataset can increase your model's performance and also reduce the chances of overfitting.
Cross-validation
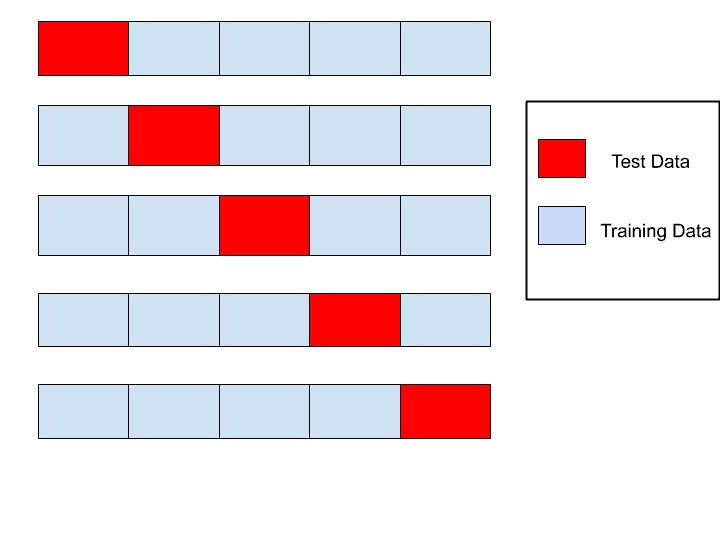
Sometimes the amount of data doesn't affect overfitting. At such times dividing the data and training the model on different partitions may work. This technique is called k-fold cross-validation, where we split our dataset into k groups or folds. Most of the time the data set is divided into two parts training dataset(80%) and the test dataset(20%). In k-fold cross-validation, we split the dataset into train and test and iterate it until each group has been used as a testing set too. This allows us to use all the datasets for training and avoid overfitting.
Feature Selection
A training dataset has many attributes in it, it's important to select the important attributes or columns as features for training the model. A famous example to understand feature selection is the life satisfaction model. If a model is trained on the uninformative column such as the country's name. In that case, a complex model may detect patterns like the fact that all countries in the training data with a w in their name have a life satisfaction greater than 7: New Zealand(7.3), Norway(7.4), Sweden(7.2) and Switzerland(7.5). This w-satisfaction rule developed by the model fails when to it comes to countries like Rwanda and Zimbabwe which have very low life satisfaction. Factors like Happiness Index, Wealth, Economy, Region, and Health are good examples of Features for the model to train on. Thus it's important to train the machine learning model only on useful features to prevent the model from making useless patterns and overfitting the data.

Regularization
A good way to avoid model overfitting is to Regularize the model i.e limit it or constrain it from learning complex patterns from the data. The fewer degree of freedom it has, the harder it will be for it to overfit the data. The two methods to regularize a machine learning model are :
Ridge models
Lasso models
More information about the Regularization techniques can be found in the above article.
Data Augmentation
Data Augmentation is generally done in deep-learning models to increase the number of Data. As mentioned in the 1st point increasing data may help to reduce model overfitting and make the model generalize well. Data augmentation is a data analysis technique used to increase the amount of training data by making slight modifications to already existing data. This acts as a regularizer and helps reduce overfitting. It can be done by taking mirror images, Blurring the image slightly, increasing or decreasing the brightness of the image and rotating the image at different angles.


Make sure to keep the balance between augmented data and real data. Sometimes using more augmented data increases the loss of the model.
Early stopping
Early stopping is a different way to regularize iterative learning algorithms. The idea behind early stopping is to stop training as soon as the test/validation error reaches a minimum.
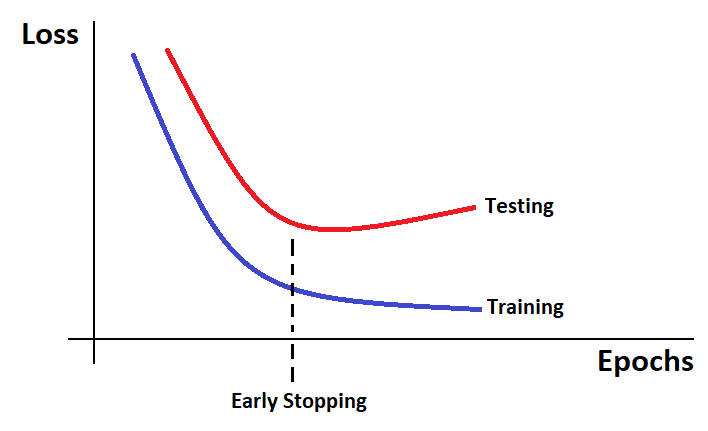
Epoch is the amount of iteration a machine learning model does through the dataset. In simple words, Epoch is the amount of passes a training data takes around the algorithm. In the above graph, as the epochs go by the algorithm learn's and its prediction loss goes down on the training dataset along with the test dataset. After a while though, the validation test error stops decreasing and starts to go back up. This indicates that the model has started to overfit the training data. With early stopping, we just stop training as soon as the test error reaches the minimum.

Wrapping up !

That's what happens when a overfit model is told to predict on the test dataset.

The above random forest model has scored 100% accuracy on a dataset and, now you know what's wrong with the model.
Thank You!
What's next?
Maybe next time we jump into code and overfit a model and then try to generalize it with one of the methods listed above.
Thank you for reading the blog. Goodbye.


